Im Vergleich zu den immer größeren Sprachmodellen (LLMs) ist das AMD-135M kompakt, vielseitig und zielgerichtet und eignet sich daher ideal für private und spezialisierte Unternehmensanwendungen.

Die AMD-135M-Modelle gehören zur Llama-Familie und sind in zwei Versionen erhältlich:
Eine Version ist das Basismodell AMD-135M, auch bekannt als AMD-Llama, das bis zu 670 Milliarden Tokens umfasst und auf acht MI250-64GB-Beschleunigern innerhalb von sechs Tagen trainiert wurde.
Die zweite Version ist das verbesserte AMD-Llama 135M-Code, das zusätzlich 20 Milliarden Tokens enthält und sich auf Programmierung fokussiert. Dieses Modell wurde innerhalb von vier Tagen auf derselben Hardware trainiert.
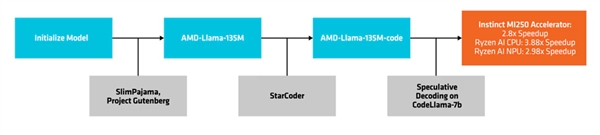
AMD nutzt die Methode des spekulativen Decodings, um mehrere Kandidaten in einem einzigen Vorwärtsschritt durch ein kleineres Entwurfsmodell zu erstellen, die dann von einem größeren, genaueren Zielmodell überprüft oder korrigiert werden.
Dieser Ansatz ermöglicht die gleichzeitige Generierung mehrerer Tokens, ohne die Leistung zu beeinträchtigen, und reduziert den Speicherbedarf, führt jedoch aufgrund mehrerer Datentransaktionen zu einem Anstieg des Stromverbrauchs.
AMD testete die Leistung der Inferenzdecodierung mit dem AMD-Llama-135M-Code als Entwurfsmodell für das CodeLlama-7b.
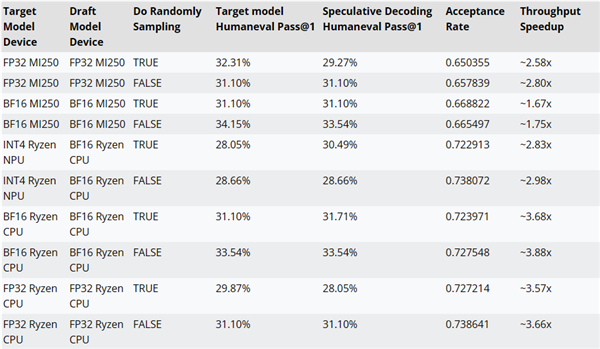
Zum Beispiel kann die Leistung auf dem MI250-Beschleuniger um bis zu 2,8-fach, auf KI-Prozessoren von Ryzen um bis zu 3,8-fach und auf NPUs in Ryzen um bis zu 2,8-fach verbessert werden.

Der Trainingscode, der Datensatz und andere Ressourcen für AMD-135M-Modelle stehen derzeit unter der Apache-2.0-Lizenz zur Verfügung.
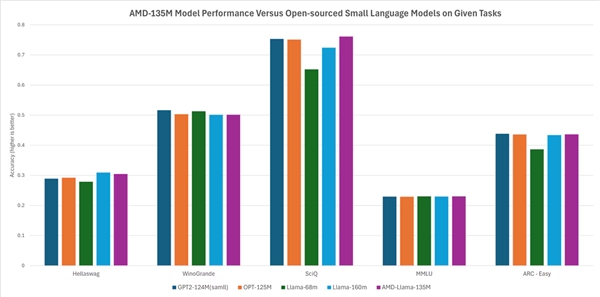
Laut AMD ist die Leistung vergleichbar oder sogar besser als bei anderen Open-Source-Modellen. Zum Beispiel übertrifft es Modelle wie Llama-68M und LLama-160M bei Aufgaben wie Hellaswag, SciQ und ARC-Ease und übertrifft Modelle wie ETP2-124M und OPT-125M bei Aufgaben wie Hellaswag, WinoGrand, SciQ, MMCU und ARC-Ease.