AMDは“AMD-135 M”という最初の小型言語モデル(SLM)をリリースしています。
ますます大きな大型言語モデル(LLM)と比較して、AMD-135 Mはよりコンパクトで柔軟であり、特定の目標に特化し、プライベートおよび専門企業配備に最適な選択となります。

AMD-135 Mモデルは「ラクダ」シリーズの一部であり、2つのバージョンが提供されます。
1つ目はベースモデルである**“AMD-Llama-135 M”**です。最大6700億トークンを持ち、8つのInstinct MI250 64GBアクセラレータを用いて6日間トレーニングされました。
2つ目は拡張版である**“AMD-LAMA-135 M-CODE”**で、追加の200億トークンを含み、プログラミング向けに特化されています。同じハードウェアで4日間のトレーニングが行われました。
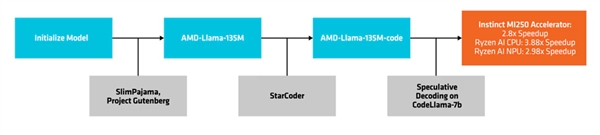
プロセスの作成と導入
AMDは**“推定復号”**と呼ばれる方法を使用しています。この方法では、小型の草稿モデルによって一度の前方伝搬で複数の候補トークンを生成し、その後より大きく正確なターゲットモデルによって検証または修正が行われます。
この手法は、データトランザクションが増えることで消費電力が増加するものの、性能に影響を与えることなく複数のトークンを同時に生成し、メモリ使用量を低減するのに役立ちます。
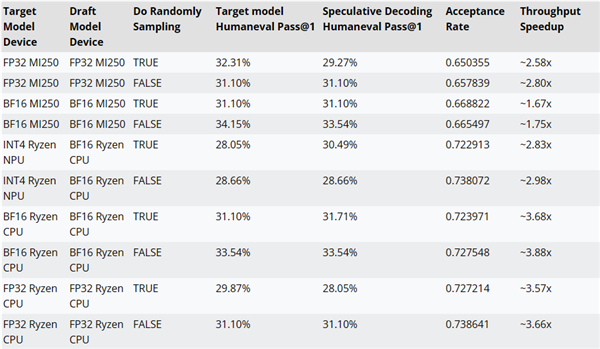
AMDは草稿モデルとしてCodeLlama-7Bを使用し、AMD-Llama-135 M-CODEにより推論復号の性能改善をテストしました。
例えば、MI 250アクセラレータでは約2.8倍、Ryzen AI CPUでは約3.88倍、Ryzen AI NPUでは約2.98倍の性能向上が確認されました。

AMD-135 Mモデルのトレーニングコード、データセット、およびその他のリソースはApache 2.0のもとでオープンソースとなっています。
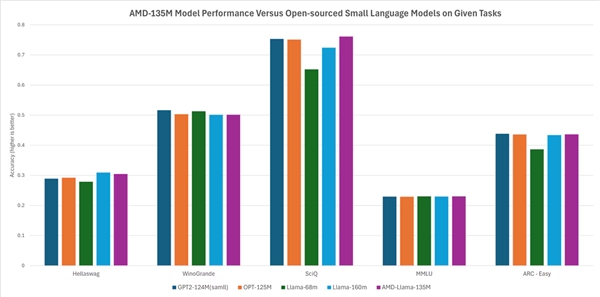
AMDによれば、その性能は他のオープンソースモデルとほぼ同等か若干上回っています。例えば、HellaSwag、SciQ、ARC-EasyといったタスクではLlama-68 MやLlama-160 Mよりも優れ、HellaSwag、WinoGrande、SciQ、MMLU、ARC-EasyといったタスクではGPT-2 124MやOPT-125Mに匹敵するパフォーマンスを示しています。