Comparé aux grands modèles linguistiques (LLM) de plus en plus grands, l'AMD-135M est compact, plus flexible et spécifiquement ciblé, ce qui le rend idéal pour les déploiements d'entreprises privées et spécialisées.

Les modèles AMD-135M font partie de la famille Llama et sont disponibles en deux versions :
L'un est le modèle de base, "AMD-Llama-135M", avec jusqu'à 670 milliards de jetons et formé sur huit accélérateurs instinct MIM250 64 Go pendant six jours.
La deuxième version est la version améliorée "AMD-Llama-135M-code", qui comprend un supplément de 20 milliards de jetons axés sur la programmation, formés sur le même matériel pendant quatre jours.
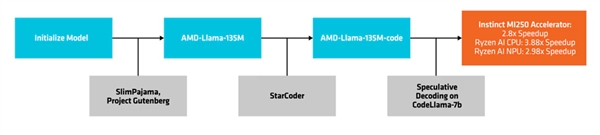
Processus de création et de déploiement
AMD utilise une méthode appelée "décodage spéculatif" pour générer plusieurs jetons candidats en un seul passage vers l'avant à travers un modèle de projet plus petit, qui sont ensuite vérifiés ou corrigés par un modèle cible plus grand et plus précis.
Cette approche facilite la génération de plusieurs jetons simultanément sans compromettre les performances et réduit l'empreinte mémoire, bien qu'elle entraîne une augmentation de la consommation d'énergie en raison de plus de transactions de données.
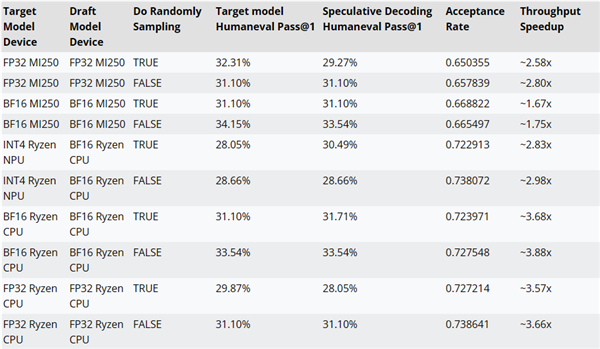
AMD a testé les améliorations de performance du décodage d'inférence en utilisant le code AMD-Llama-135M comme modèle de projet pour CodeLlama-7b.
Par exemple, les performances peuvent être améliorées jusqu'à ~ 2.8x sur les accélérateurs MI250, jusqu'à ~ 3.88x sur les processeurs Ryzen AI et jusqu'à ~ 2.98x sur les NPU Ryzen AI.

Le code de formation, les jeux de données et d'autres ressources pour les modèles AMD-135M ont été open-source sous la licence Apache 2.0.
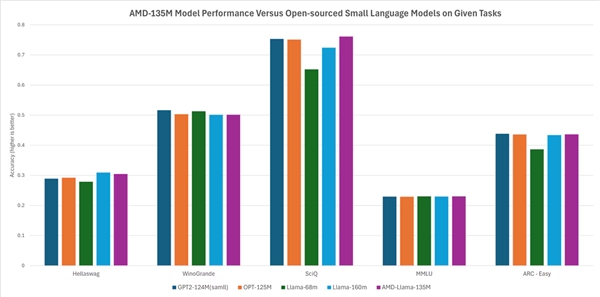
Selon AMD, ses performances sont égales ou légèrement supérieures à celles des autres modèles open-source. Par exemple, il surpasse les modèles comme Llama-68M et LLama-160M dans des tâches telles que Hellaswag, SciQ et ARC-Easy, et fonctionne de manière comparable à des modèles comme GTP2-124MN et OPT-125M dans des tâches comme Hellaswag, WinoGrande, SciQ, MMLU et ARC-Easy.