Rispetto ai sempre più grandi modelli linguistici (LLMs), l'AMD-135m è compatto, più flessibile e specificamente mirato, rendendolo ideale per implementazioni aziendali private e specializzate.

I modelli AMD-135m fanno parte della famiglia Llama e sono disponibili in due versioni:
Una è il modello di base, "AMD-Llama-135m", che vanta fino a 670 miliardi di token ed è addestrato su otto acceleratori Instinct MI250 64GB in sei giorni.
La seconda versione è il potenziato "AMD-Llama-135m-code", che include ulteriori 20 miliardi di token focalizzati sulla programmazione, addestrato sullo stesso hardware per quattro giorni.
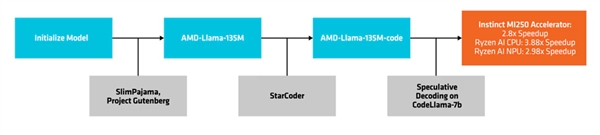
AMD utilizza un metodo chiamato "decodifica speculativa" per generare più token candidati in un unico passaggio attraverso un modello di progetto più piccolo, che vengono poi verificati o corretti da un modello di destinazione più grande e accurato.
Questo approccio facilita la generazione di token multipli contemporaneamente senza compromettere le prestazioni e riduce l'impronta di memoria, anche se porta ad un aumento del consumo di energia a causa di più transazioni di dati.
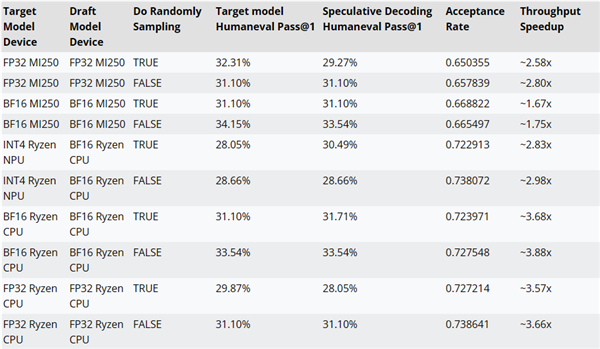
AMD ha testato i miglioramenti prestazionali della decodifica inferenziale utilizzando il codice AMD-Llama-135m come modello di progetto per CodeLlama-7b.
Ad esempio, le prestazioni possono essere migliorate fino a ~2,8x su acceleratori MI250, fino a ~3,88x su CPU Ryzen AI, e fino a ~2,98x su Ryzen AI NPU.

Il codice di formazione, i dataset e le altre risorse per i modelli AMD-135m sono stati rilasciati sotto licenza Apache 2.0.
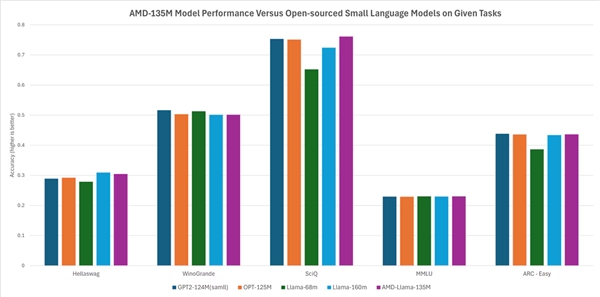
Secondo AMD, le sue prestazioni sono alla pari o leggermente migliori rispetto ad altri modelli open-source. Ad esempio, supera modelli come Llama-68m e Llama-160m in compiti come Hellaswag, SciQ e ARC-easy, ed esegue comparabilmente a modelli come GPT-2-124M e OPT-125M in compiti come Hellaswag, WinoGrande, SciQ, MMLU e ARC-easy.