AMD는 'AMD-135M'이라는 첫 번째 소형 언어 모델(SLM)을 발표했습니다. AMD-135M은 점점 커지는 대형 언어 모델(LLM)보다 더 컴팩트하고 유연하며, 특정 목표에 특화되어 사설 및 전문 기업 배포에 이상적입니다.

AMD-135M 모델은 낙타 시리즈의 일부이며, 다음 두 가지 버전을 선택할 수 있습니다. 하나는 기본 모델인 **'AMD-Llama-135M'**으로, 최대 6700억 토큰을 보유하고 있습니다. 이 기본 모델은 8개의 Ininstinct MI250 64GB 가속기로 6일 동안 학습되었습니다. 두 번째 버전인 **'AMD-LAMA-135M-CODE'**는 추가 200억 토큰을 포함하며, 프로그래밍에 집중하여 동일한 하드웨어에서 4일간 학습이 이루어졌습니다.
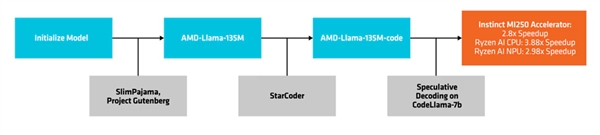
개발 및 배포 프로세스
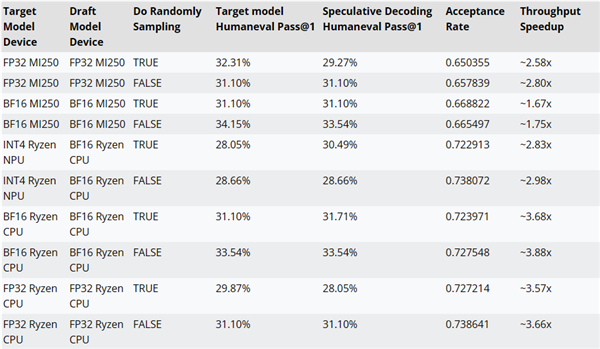
AMD는 **'추측 디코딩'**이라는 방법을 사용하여, 작은 초안 모델을 통해 한 번의 포워드 전송으로 여러 후보 토큰을 생성한 다음, 더 크고 정확한 대상 모델에서 이를 검증 및 보정합니다. 이 방법을 통해 성능에 영향을 주지 않으면서 동시에 여러 토큰을 생성하고 메모리 사용량을 줄일 수 있습니다. 그러나 데이터 트랜잭션의 증가로 인해 전력 소비량이 증가할 수 있습니다. AMD는 AMD-Llama-135M-코드를 CodeLlama-7b의 초안 모델로 사용하여 추리 번역 코드의 성능을 테스트했습니다. 예를 들어, MI250 액셀러레이터에서는 약 2.8배, Ryzen AI CPU에서는 약 3.88배, Ryzen AI NPU에서는 약 2.98배 성능 향상이 나타났습니다.

AMD-135M 모델의 학습 코드, 데이터 세트 및 기타 리소스는 Apache 2.0 라이센스 하에 공개되었습니다.
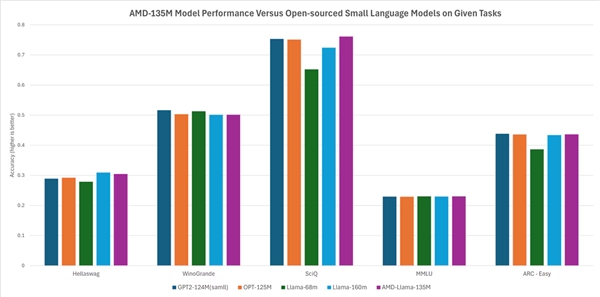
AMD에 따르면, 이 모델은 다른 오픈 소스 모델과 동일하거나 약간 더 높은 성능을 제공합니다. 예를 들어, Hellaswag, SciQ, ARC-Easy와 같은 퀘스트에서는 Llama-68M과 Llama-160M보다 우수하고, Hellaswag, WinoGrande, SciQ, MMLU, ARC-Easy 등의 미션에서는 GTP2-124MN과 OPT-125M과 비슷한 성능을 나타냅니다.