AMD has released its first Small Language Model (SLM) called "AMD-135M".
Compared to the increasingly large Large Language Models (LLMs), the AMD-135M is compact, more flexible, and specifically targeted, making it ideal for private and specialized enterprise deployments.

The AMD-135M models are part of the Llama family and are available in two versions:
One is the base model, "AMD-Llama-135M", boasting up to 670 billion tokens and trained on eight Instinct MIM250 64GB accelerators over six days.
The second version is the enhanced "AMD-Llama-135M-code", which includes an additional 20 billion tokens focused on programming, trained on the same hardware for four days.
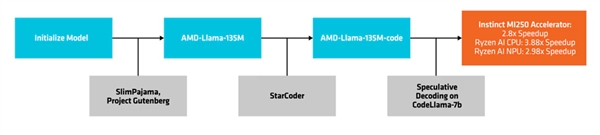
Creation and Deployment Process
AMD employs a method called "speculative decoding" to generate multiple candidate tokens in a single forward pass through a smaller draft model, which are then verified or corrected by a larger, more accurate target model.
This approach facilitates the generation of multiple tokens simultaneously without compromising performance and reduces the memory footprint, though it does lead to an increase in power consumption due to more data transactions.
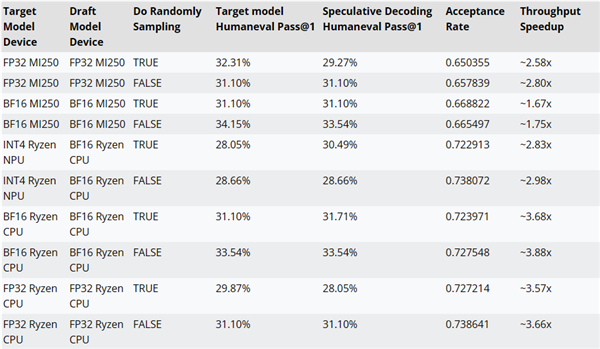
AMD tested the performance improvements of inference decoding using the AMD-Llama-135M-code as a draft model for CodeLlama-7b.
For example, performance can be improved by up to ~2.8x on MI250 accelerators, up to ~3.88x on Ryzen AI CPUs, and up to ~2.98x on Ryzen AI NPUs.

The training code, datasets, and other resources for the AMD-135M models have been open-sourced under the Apache 2.0 license.
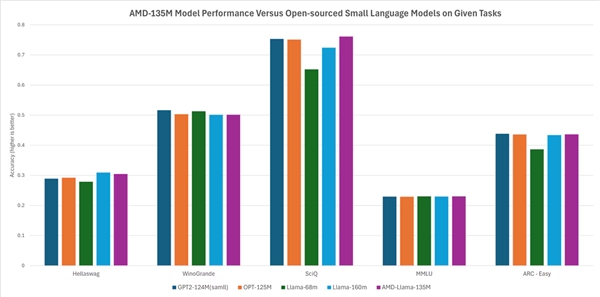
According to AMD, its performance is on par with or slightly better than other open-source models. For instance, it outperforms models like Llama-68M and LLama-160M in tasks such as Hellaswag, SciQ, and ARC-Easy, and performs comparably to models like GTP2-124MN and OPT-125M in tasks like Hellaswag, WinoGrande, SciQ, MMLU, and ARC-Easy.