AMD lançou seu primeiro modelo de linguagem pequena (SLM) chamado "AMD - 135m".
Comparado com os modelos de linguagem grandes (LLM), o AMD - 135m é compacto, mais flexível e especificamente direcionado, tornando-o ideal para implantações em empresas privadas e especializadas.

Os modelos AMD - 135m fazem parte da família Llama e estão disponíveis em duas versões:
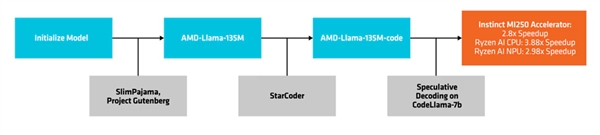
AMD emprega um método chamado "Decodificação Especulativa" para gerar múltiplas fichas candidatas em uma única passagem através de um modelo de rascunho menor, que são então verificadas ou corrigidas por um modelo alvo maior e mais preciso.
Essa abordagem facilita a geração de múltiplas fichas simultaneamente sem comprometer o desempenho e reduz a pegada de memória, embora leve a um aumento no consumo de energia devido a mais transações de dados.
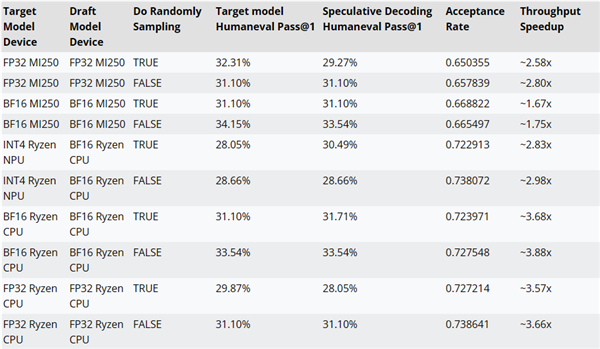
AMD testou as melhorias de desempenho da decodificação de inferência usando o código AMD - Llama - 135m como um modelo de rascunho para CodeLlama - 7b.
Por exemplo, o desempenho pode ser melhorado até ~2.8x em aceleradores MI250, até ~3.88x em CPUs Ryzen IA e até ~2.98x em NPUs Ryzen AI.

O código de treinamento, conjuntos de dados e outros recursos para os modelos AMD - 135m têm sido open source sob a licença Apache 2.0.
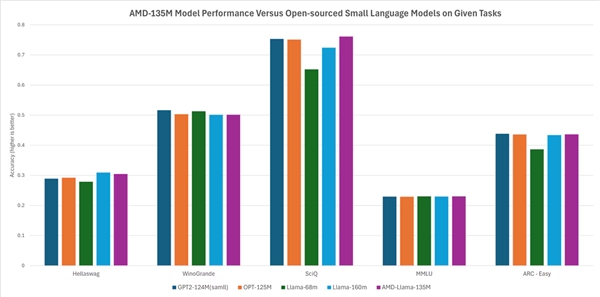
De acordo com a AMD, seu desempenho está em pé de igualdade ou ligeiramente melhor do que outros modelos de código aberto. Por exemplo, ele supera modelos como Llama - 68m e Llama - 160m em tarefas como Hellaswag, SciQ e ARC - Easy, e realiza comparavelmente com modelos como GTP2 - 124MN e Opt - 125m em tarefas como Hellaswag, WinoGrande, SciQ, MMLU e ARC - Easy.